난 흐름을 좋아한다.
역사도 흐르고, 강물도 흐르고, 우리의 인생도 흐른다.
그래서 PostgreSQL 아키텍처를 흐르면서 이해를 하려 한다. (데이터의 흐름)
시작 - 시스템의 흐름은 요청에 의해 시작한다.
Client (클라이언트)
- 클라이언트는 TCP/IP or 소켓을 통해 서버에 요청을 보냄.
- 클라이언트가 Query를 실행하면, 시스템에서 최초 Postmaster 프로세스가 맞이한다. (도어맨?)
- Client Application
- 사용자가 PostgreSQL에 연결하는 애플리케이션 (예: 웹 애플리케이션, BI 툴, API 서버 등)
- API를 통해 데이터베이스 요청을 수행
- Client Interface Library
- PostgreSQL과 통신하기 위한 클라이언트 라이브러리 (libpq, JDBC, psycopg2 등)
- 클라이언트 애플리케이션이 PostgreSQL과 SQL 쿼리 및 결과를 주고받을 때 사용
- Client Application
Server(서버) - 처리
먼저 처리를 위해서는 아래 3가지 영역(부서?)이 필요하고 각 영역의 처리 담당자와 역할을 소개한다.
| 1. 프로세스(Process) | 2. 메모리(RAM) | 3. 디스크(Disk) / 파일(File) |
1. 프로세스(Process)
; 프로세스라는 조직안에서는 2개의 파트로 구성되어 있고, 역할별로 일꾼들이 있다.
Server Processes (서버 프로세스)
- Postmaster (PostgreSQL Master Process , Postmaster Daemon Process, edb-postgres)
최초 요청 Query를 맞이한 Postmaster는 PostgreSQL에서 최상위 프로세스로, 클라이언트 연결을 관리함.
새로운 (연결) 요청이 오면 맞이하여, Backend Process(백엔드 프로세스)를 생성함. - Backend Processes (Postgres Backend Process)
백엔드 프로세스는 클라이언트와 1:1로 연결되며,
요청(Query)를 실행하고 데이터를 검색한 후 클라이언트에 반환함.
Background Utility Processes (백그라운드 프로세스)
; PostgreSQL 성능 유지 및 장애 복구에 필수적인 역할
- Autovacuum
MVCC (Multi-Version Concurrency Control) 구조로 인해 DELETE/UPDATE 후 삭제된 불필요한 튜플(Dead Tuple)을 자동으로 정리하여 성능 저하를 방지함.
(튜플은 생활하면서 발생하는 쓰레기 같은 것이라고 이해했음. 튜플에 대해서는 Vaccum과 함께 별도 세션에서 또..)
Vacuum 작업을 수행하여 데이터베이스를 최적화. (진공청소기로 방정리 해주는... 매우 그레이트 어마무시하게 중요!) - Logger (Sys Logger)
모든 PosgreSQL의 활동을 기록하는 로그 관리 프로세스. (나의 생활을 기록해주는.. 난 그럼 유명인?.. 죄송..)
log_text_lines 파일에 SQL Query, 오류 메세지 등을 저장. - Stats Collector
데이터베이스의 통계를 수집, 쿼리 최적화 및 성능을 모니터링 함.
pg_stat_*** 뷰를 통해 쿼리 성능 분석 가능. - WAL Writer
WAL(Write-Ahead Logging) 로그를 디스크에 기록하는 프로세스.
데이터 변경 사항을 WAL 파일에 기록한 후 실제 데이터 파일에 반영함. - WAL Receiver & WAL Sender
스트리밍 복제(Streaming Replication)를 수행하는 프로세스
WAL Sender가 마스터에서 WAL 데이터를 보내고, WAL Receiver가 슬레이브에서 이를 수신하여 적용. - Checkpointer
일정 주기마다 데이터를 디스크에 저장하고 체크 포인트를 생성. (모든 작업은 매번 디스크에 쓰지 않구나 추측)
체크포인트는 크래시 발생 시 복구 시점을 결정하는 중요한 역할도 함. - BGWriter (Background Writer)
변경된 데이터를 디스크로 비동기로 기록하는 프로세스.
데이터베이스의 성능을 향상(최적화)시키기 위해 캐시에서 디스크로 데이터를 저장하는 역할. - Archiver
WAL 로그를 압축 및 보관하여 장애 발생 시 복구할 수 있도록 보관함. - Logical Replication Launcher
논리적 복제(Logical Replication) 기능을 담당하는 프로세스
2. 메모리 (RAM)
작업을 위해서는 작업자들이 일을 처리하기 위한 작업공간이 필요하다. (개인책상, 회의실, 비품실 등등..)
PostgreSQL은 공유메모리와 개별 프로세스 메모리로 나뉨.
- Individual Memory (개별 프로세스 메모리) (Per Backend Memory, Backend Buffer)
각 클라이언트 세션마다 할당되며, 세션이 종료되면 메모리가 해제 됨.
- maintenance_work_mem: VACUUM, CREATE INDEX와 같은 유지보수 작업에 사용되는 메모리.
- work_mem: 각 쿼리 실행 시 사용되는 메모리 (정렬, 해시 조인, 해시 집계 등).
- autovacuum_work_mem: autovacuum 프로세스에서 사용하는 메모리.
- temp_buffer: 개별 쿼리에서 임시 데이터 저장 메모리.
- catalog_cache: 시스템 카탈로그 테이블을 캐싱하여 빠른 접근 가능.
- optimizer/executor: 쿼리 최적화 및 실행을 위한 메모리.
더 자세한 내용 : https://jaihuni.tistory.com/entry/PostgreSQL-Backend-Buffer
- Shared Memory (PostgreSQL 인스턴스 전체에서 공유하는 메모리, Shared Buffer)
공유 메모리는 PostgreSQL 인스턴스 전체에서 공용으로 사용되며, 서버 성능을 결정하는 중요한 요소!
- shared_buffers: Heap 및 Index 데이터를 캐싱하여 디스크 I/O를 줄이고 성능을 향상시킴.
- wal_buffers: WAL 로그를 임시로 저장하는 메모리 영역, shared_buffers와 별도로 관리되는 메모리 공간.
- Temp Buffers: 각 세션이 필요할 때 사용하는 임시 테이블 데이터를 저장.
- CLOG Buffers: 트랜잭션 상태를 관리하는 Commit Log (CLOG) 버퍼. 각 트랜잭션의 커밋 상태를 추적.
MVCC(Multi-Version Concurrency Control) 구현을 위한 필수 요소 - Other Buffers: 다양한 내부 처리에 사용되는 추가적인 메모리 영역.
- Lock Space: 데이터베이스의 잠금 정보를 관리하는 공유 메모리 영역,
max_locks_per_transaction 파라미터로 설정
더 자세한 내용 : https://jaihuni.tistory.com/entry/PostgreSQL-Shared-Buffer
3. 디스크 (Disk) / 파일 (File) - Data Cluster (데이터 저장)
처리 업무는 모두 작업공간에 계속 쌓아놓고 일할 수 없다. 처리 완료된 내용은 별도 공간에 저장함.
PostgreSQL은 데이터를 디스크에 저장하며, 아래 유형의 파일 시스템을 사용.
- Storage Manager: Data Files - Heap and Index
- 실제 데이터(테이블,Heap)와 인덱스(Index)는 랜덤 읽기/쓰기(Random Access I/O)를 사용하여 저장됨.
- shared_buffers를 통해 데이터가 캐시되며, 필요할 때만 디스크에서 읽어온다.
- Sub-directories (Segments)
- 데이터 파일이 저장되는 물리적 디렉터리 구조.
- WAL (Write-Ahead Logging) Files
- 모든 트랜잭션 변경 사항을 기록하는 WAL 로그를 저장.
- WAL 로그는 순차적인 방식(Sequential Writing)으로 기록되어 빠른 성능을 제공.
- 만약 데이터가 손상되면 WAL 로그를 사용하여 복구할 수 있음.
- Archived Files (아카이브 모드 활성화 시)
- WAL 로그를 백업하여 장애 발생 시 복구할 수 있도록 보관.
- Log Files
- PostgreSQL의 운영 로그 파일 (SQL 실행 기록, 오류 로그 등)
- Lock File
- PostgreSQL이 실행 중인지 확인하는 파일
이제 데이터를 흘려보자.
📌 PostgreSQL의 데이터 흐름 (Query Execution Flow)
1️⃣ 클라이언트가 SQL 쿼리를 요청하면, Postmaster가 이를 수신,
2️⃣ Postmaster는 Backend Process를 생성하여 요청을 처리하고
3️⃣ Backend Process는 Shared Memory의 shared_buffers를 확인하여 데이터 조회,
4️⃣ 데이터가 shared_buffers에 없으면 디스크에서 데이터를 읽고 shared_buffers에 로드함.
5️⃣ 변경 사항이 있으면 WAL Buffers에 먼저 기록, WAL Writer가 WAL Buffers → WAL 파일로 저장
6️⃣ (Background) 일정 시간(Checkpoint)마다 Checkpointer가 변경된 데이터를 디스크에 저장하여 영구적으로 반영,
7️⃣ (Background) Autovacuum이 주기적으로 실행되어 불필요한 Dead Tuple을 정리하여 성능 유지.
8️⃣ 클라이언트에 쿼리 결과를 반환한다.
위 흐름을 이제 도식화해서 한눈으로 보자.
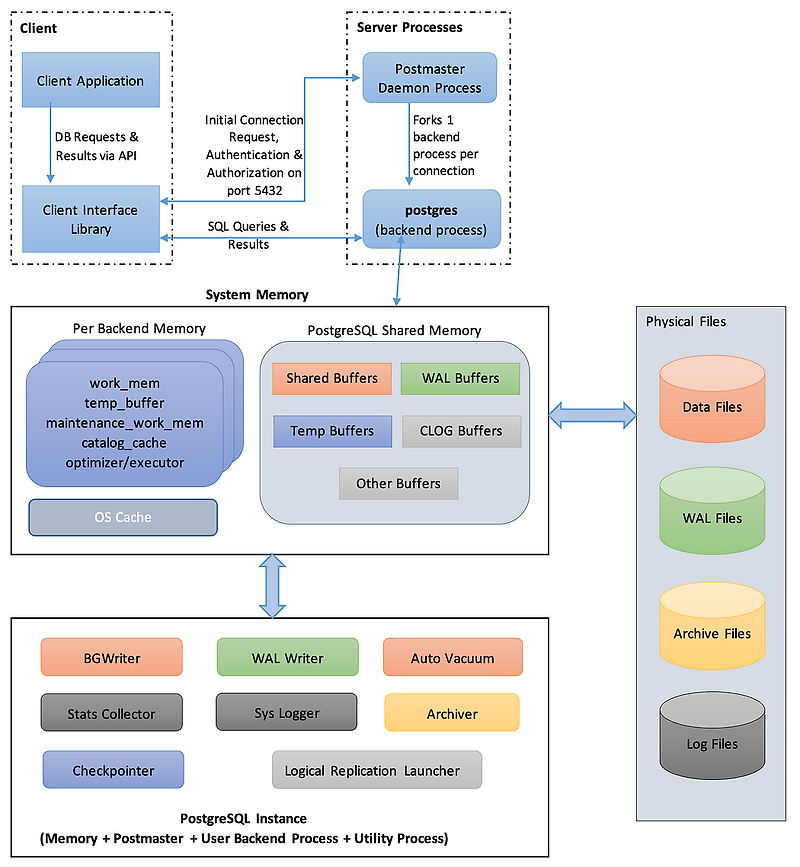
다른 형태
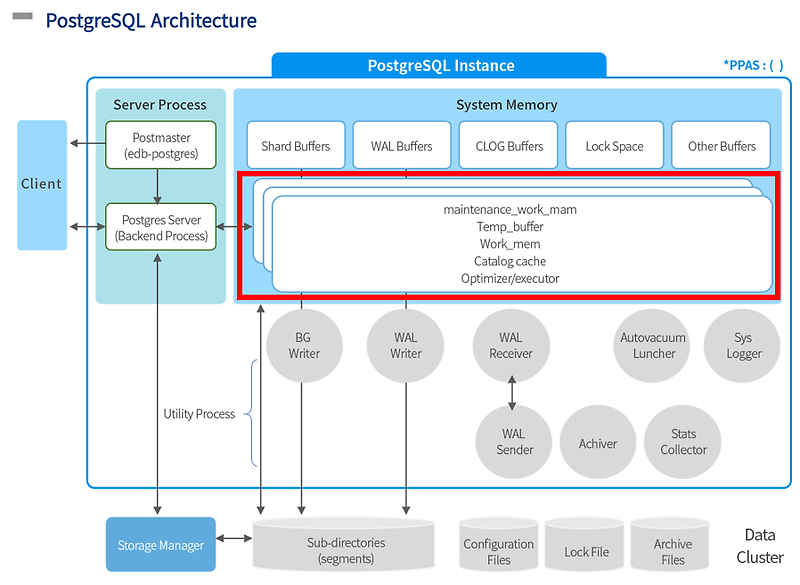
💡 PostgreSQL의 성능을 최적화하려면 중요한 부분. (더 자세히 다룰 내용들)
1️⃣ 메모리 최적화
- shared_buffers, work_mem, maintenance_work_mem 설정을 조정하여 성능 향상
2️⃣ 자동 관리 프로세스 튜닝
autovacuum 설정을 조정(개인적으로 수동 Vacuum을 선호함) 하여 Dead Tuple을 빠르게 정리.- checkpoint_timeout, checkpoint_completion_target 설정으로 Checkpoint 최적화
3️⃣ WAL 및 복구 관리
- wal_buffers, wal_writer_delay 조정하여 트랜잭션 처리 성능 개선
- archive_mode 활성화로 WAL 로그를 안전하게 보관
4️⃣ 디스크 I/O 최적화
- random_page_cost, seq_page_cost 조정하여 쿼리 최적화
- SSD 환경에서는 effective_io_concurrency 증가
5️⃣ 쿼리 최적화 기능 강화
- JIT(Just-In-Time) Compilation 최적화
- pg_stat_statements 개선으로 성능 분석 강화
부록 : Flow 좋아하는 노래
'PostgreSQL' 카테고리의 다른 글
| PostgreSQL - Memory - Backend Buffer (0) | 2025.02.22 |
|---|---|
| PostgreSQL - Idle Session' Memory (0) | 2025.02.22 |
| PostgreSQL Query Optimization : 실행 계획 - Scan 방식의 종류 (0) | 2024.12.29 |
| PostgreSQL Query Optimization : 실행 계획 이해하기 (0) | 2024.12.21 |
| PostgreSQL Query Optimization : 더 깊은 이론 - 알고리즘 (0) | 2024.12.21 |