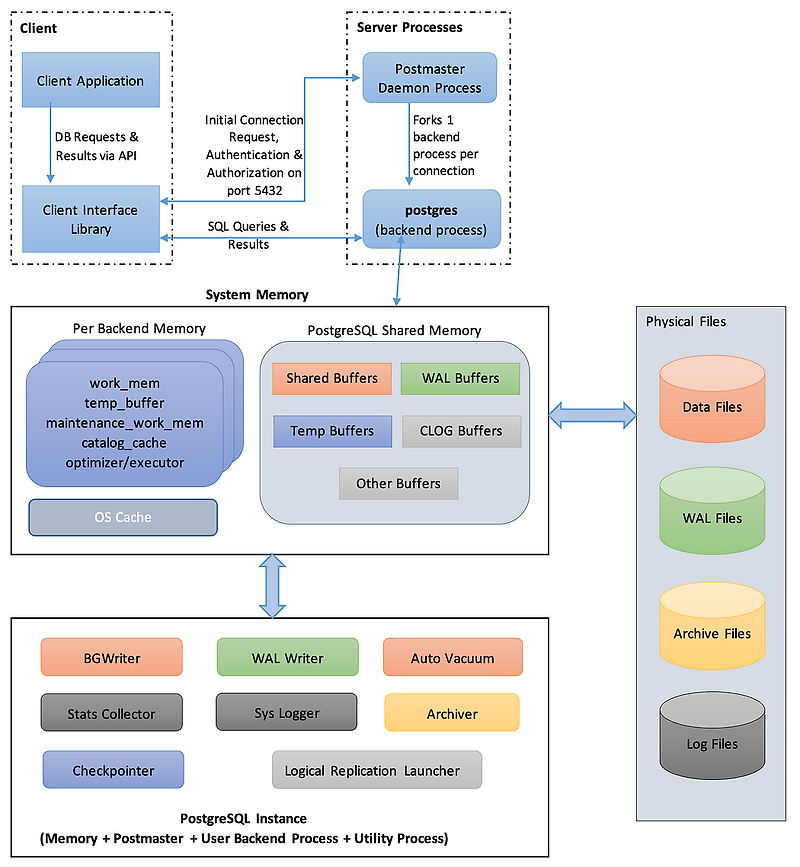
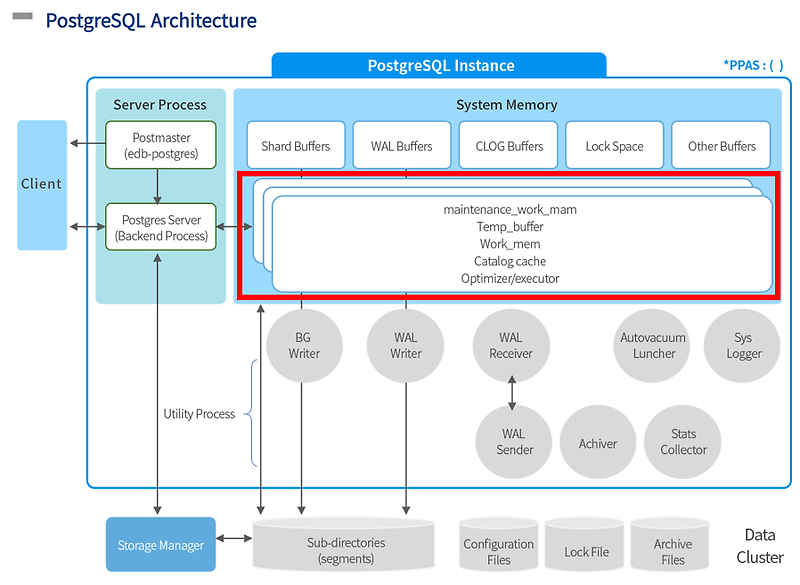
PostgreSQL의 VACUUM은 MVCC(다중 버전 동시성 제어, Multi-Version Concurrency Control)로 인해 발생하는 Dead Tuple(사용되지 않는 데이터)을 정리하는 과정.
- VACUUM이 없으면 PostgreSQL 테이블 크기가 계속 증가하고 성능이 저하됨.
- Dead Tuple이 많아지면 SELECT 속도가 느려지고, INSERT/UPDATE 시 불필요한 I/O가 증가.
- VACUUM을 효율적으로 설정하면 PostgreSQL 성능을 최적화할 수 있음.
1️⃣ VACUUM이 필요한 이유
🔹 PostgreSQL은 DELETE와 UPDATE 시 데이터를 실제로 삭제하지 않는다!
PostgreSQL의 MVCC 특성상 DELETE 또는 UPDATE가 실행되면 기존 데이터를 변경하지 않고 새로운 버전을 생성한다.
- DELETE: 데이터가 즉시 삭제되지 않고 삭제 표시(xmax 값이 설정됨)만 됨.
- UPDATE: 기존 데이터가 Dead Tuple이 되고, 새로운 Tuple이 생성됨.
UPDATE user SET name = 'Alice Smith' WHERE id = 1;
실제 데이터 변경 과정
| ctid | id | name | xmin | xmax |
| (0,1) | 1 | Alice | 1001 | 1002 |
| (0,2) | 1 | Alice Smith | 1002 | NULL |
✅ Dead Tuple이 많아지면 VACUUM이 필요함!
✅ VACUUM이 없으면 테이블 크기가 계속 증가하며 성능 저하 발생
2️⃣ VACUUM의 종류
PostgreSQL에서는 여러 가지 VACUUM 방식이 있다.
| VACUUM 종류 | 설명 | Dead Tuple 제거 | 디스크 공간 회수 | Exclusive Lock 필요 |
| VACUUM | 기본적인 Dead Tuple 정리 | ✅ | ❌ | ❌ |
| VACUUM ANALYZE | VACUUM + 통계 정보 갱신 (Query Planner 최적화) |
✅ | ❌ | ❌ |
| VACUUM FULL | Dead Tuple 제거 + 디스크 공간 반환 | ✅ | ✅ | ✅ |
| AUTOVACUUM | 자동으로 백그라운드에서 실행됨 | ✅ | ❌ | ❌ |
✅ 일반적으로는 AUTOVACUUM을 사용하지만, 필요 시 VACUUM FULL을 실행해야 함.
3️⃣ VACUUM 동작 과정
(1) VACUUM 기본 동작 원리
- Dead Tuple 스캔: 테이블을 읽으며 Dead Tuple을 찾음.
- Dead Tuple을 Free Space Map(FSM)에 등록: 추후 INSERT가 같은 공간을 활용할 수 있도록 함.
- Index 유지보수: 인덱스에서 참조되지 않는 Tuple을 제거.
- Transaction ID Wraparound 방지: autovacuum_freeze_max_age를 초과한 경우 FREEZE 실행.
✅ VACUUM을 실행하면 테이블 크기가 줄어드는 것이 아니라, Dead Tuple이 제거되고 기존 공간을 재사용 가능하게 됨. ✅ 디스크 공간을 줄이려면 VACUUM FULL을 실행해야 함.
(2) VACUUM ANALYZE
- VACUUM과 ANALYZE를 함께 실행하여 Dead Tuple 정리 후 통계 정보를 업데이트.
- Query Planner가 최신 통계를 반영하여 최적의 실행 계획을 선택 가능.
- SELECT 성능이 저하된 경우 VACUUM ANALYZE를 실행하면 해결될 가능성이 큼.
✅ 실행 방법
VACUUM ANALYZE user;✅ Query Planner가 통계를 활용하는지 확인
EXPLAIN ANALYZE SELECT * FROM user WHERE name = 'Alice';- Seq Scan(전체 테이블 스캔)이 발생하면 통계 정보가 최신이 아닐 수 있음.
(3) VACUUM FULL
- VACUUM과 다르게 테이블 크기를 실제로 줄여줌.
- Dead Tuple을 제거하고, 기존 테이블을 새로운 테이블로 재구성.
- 하지만, Exclusive Lock이 필요하기 때문에 실행 중에는 테이블을 사용할 수 없음.
✅ 실행 방법
VACUUM FULL user;✅ VACUUM FULL 실행 시 고려해야 할 점
- 테이블 크기가 줄어들지만, 잠금(Lock)이 발생하여 서비스에 영향을 줄 수 있음.
- 일반적인 운영 환경에서는 피하는 것이 좋음 (가능하면 비활성 시간대에 실행).
4️⃣ Autovacuum (자동 VACUUM)
🔹 Autovacuum이란?
- PostgreSQL은 Dead Tuple이 일정 수준을 초과하면 자동으로 VACUUM을 실행함.
- 수동으로 VACUUM을 실행하지 않아도 PostgreSQL이 최적의 시점에서 자동으로 실행.
(필자 의견)
최적의 시점에 Vacuum 이 동작해도 리소스( CPU, 메모리 )를 사용한다.
테이블 사용이 peak 인 시간에 동작한다면, 리소스 고갈로 장애로 이어질 수 있다.
필자는 Autovacuum을 선호하지 않는다.
5️⃣ Dead Tuple 및 VACUUM 상태 확인
✅ Dead Tuple 확인
autovacuum = on
autovacuum_vacuum_threshold = 500 # 기본값: 50 → 변경이 500건 이상이면 VACUUM 실행
autovacuum_vacuum_scale_factor = 0.05 # 기본값: 0.2 → 5% 변경 시 VACUUM 실행
autovacuum_naptime = 30s # 기본값: 1min → 더 자주 실행
vacuum_cost_limit = 2000 # 기본값: 200 → VACUUM 성능 향상- dead_tuple_ratio > 20%이면 VACUUM 실행 필요!
✅ 최근 VACUUM 실행 여부 확인
SELECT relname, last_vacuum, last_autovacuum
FROM pg_stat_user_tables
WHERE schemaname = 'public';
6️⃣ VACUUM 최적화 전략
✔ Dead Tuple이 많다면 VACUUM ANALYZE 실행
VACUUM ANALYZE [테이블명];✔ 테이블 크기를 줄이고 싶다면 VACUUM FULL 실행
VACUUM FULL [테이블명];✔ Autovacuum이 너무 자주 실행된다면 autovacuum_vacuum_threshold 값을 높이기
autovacuum_vacuum_threshold = 1000✔ HOT(Heap-Only Tuple) 최적화로 VACUUM 부담 줄이기
ALTER TABLE users SET (fillfactor = 80);✔ 테이블 크기가 너무 커지면 CLUSTER 실행
CLUSTER user USING user_pkey;
✅ 결론
🔹 PostgreSQL의 VACUUM은 MVCC로 인해 생성된 Dead Tuple을 정리하는 과정
🔹 VACUUM을 실행하지 않으면 테이블 크기가 계속 증가하고 SELECT 성능이 저하됨
🔹 VACUUM ANALYZE를 실행하면 Dead Tuple을 정리하고 Query Planner 통계를 최신화 가능
🔹 VACUUM FULL은 디스크 공간을 회수하지만, Exclusive Lock이 필요하여 신중하게 실행해야 함
🔹 Autovacuum을 적절히 튜닝하면 자동으로 Dead Tuple을 관리 가능
'PostgreSQL' 카테고리의 다른 글
| PostgreSQL - Tuple (0) | 2025.02.23 |
|---|---|
| PostgreSQL - MVCC (Multi-Version Concurrency Control) (0) | 2025.02.23 |
| PostgreSQL - Memory - Shared Buffer (0) | 2025.02.22 |
| PostgreSQL - Memory - Backend Buffer (0) | 2025.02.22 |
| PostgreSQL - Idle Session' Memory (0) | 2025.02.22 |